CSE 546 Machine Learning Final Project - Identifying Genre by Album Cover
Excuse the poor to mediocre quality of the banner above - it is a compressed version of a sample of the albums we used, which is still more detailed than what our algorithms interpreted. Below is a brief introduction to the project and discussion of some of the results. Underneath that, you can check out our poster presentation and project write-up.
Brief Introduction
Sonic media is interesting in that the product is sound, yet the physical package marketed to the customer has to be visual. This visual style of the album cover art usually reflects the overall tone of the album or perhaps portrays a visual representation of the album’s topic. Hence, understanding the style of an album cover is important since it gives one an idea of the type of music as well as how potentially interesting that music will be. Certain musical genres are known to be associated with a particular cover art style. For example, ambient albums tend to have more abstract, computer-generated designs, and metal albums tend to use darker colors with unusual fonts for the album title. These styles are recognizable to most human observers, and we want to test whether or not machines can also detect them.
In this project, we attempted to classify the genre of an album based on its cover art. While an important visual component, it is difficult to enunciate how style varies from image to image as well as quantify said difference. Distinct visual styles are readily apparent in various media, and entire fields are built on distinguishing between different periods of art. Hence, we thought it would be interesting to see if we can train models to identify major components of certain styles of cover art and use these models to identify the corresponding musical genre.
We define 10 different genres of music and classify each with a digit between 0 and 9. These are: ambient (0), dubstep (1), folk (2), hiphop/rap (3), jazz (4), metal (5), pop (6), punk (7), rock (8), and soul (9). The genres listed represent the 10 most common genres on Bandcamp. Next, we scraped aforementioned media platform for albums/artists. In this phase, the training dataset has been selected to have 8800 album covers and the testing dataset has 1000 randomly selected album covers. We note here that the number of albums per genre in the training set vary between 990 and 970. The testing set has an equal number of album covers per genre.
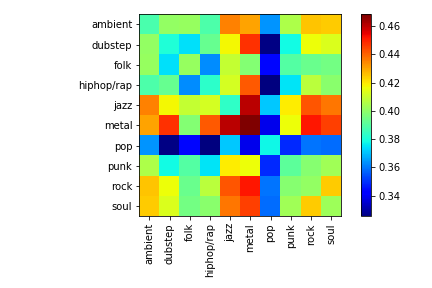
In this project, we have performed a histogram color analysis, several out of the box ML techniques, and convolutional neural nets. None of these performed in a satisfactory way, though our analyses suggest some interesting directions that could be pursued for better accuracy, as well as some fundamental differences our dataset has from other more common learning datasets. The color histograms showed that the color content alone of the album art was generally not useful for most genres, and many of the standard ML techniques from sk-learn more or less resulted in classification probabilities equal to guessing. Some overfit the data while others did not. While image classification with neural nets had some success in some genres, the overall result was poor. Averaging around 18% correctness is only slightly better than guessing for the 10 named genres.


Brief Discussion of Results
The two main antagonists in this case are related, and seem to be the type of object we are trying to classify and the labeling of the data itself. The first issue is that we are trying to classify style of an image, which is more subtle and complex than its physical structure or shape. It’s interesting to note that the models pre-trained to perform very well (>90%) on CIFAR-10 perform poorly on our dataset, suggesting some fundamental difference in what these two image datasets represent. In more standard learning problems like CIFAR-10 or MNIST (or even Imagenet) image classification, the problem is to extract some type of visible pattern or shape to detect an object, which has some type of consistent structure in the different images. In this project however, there isn’t always a consistent structure that corresponds to each genre. It would not be enough to classify simply what the image contains in this instance, as we are actually trying to relate how the objects in an image fit together in an aesthetic that is representative of a musical genre. Karayev et al attempted something similar with paintings, but even those are an easier task in that certain styles are known to have certain color palettes and brush strokes. Indeed, even the humans we tested this on did not perform well.
The other, possibly more serious, issue is that our dataset is not robust enough. Karayev et al had hundreds of thousands of paintings to choose from; we only have 9800 total to train our networks. If our dataset was similar to some of the others we have seen throughout the class, then one would believe the pretrained models would have classified the genres better. This, however, could also be related to the fact that we are not classifying images in the conventional sense. Another issue we believe is confounding our results is that genre designation is naturally fluid. For instance, of these 10 genres, several of them can be considered subgenres of another (punk and metal are subgenres of rock). We think that having more distinct genres to classify or even allowing albums to be classified as more than one genre will increase the accuracy of our results. Notice that neural networks performed the best (close to 50%) at classifying metal, which is a very specific genre. Whereas, they performed poorly on rock, which is an ambiguous, very broad designation that could include many different styles of music, ranging from indie rock to heavy metal. Instead of obtaining data that labels each album with a single genre, one could label each album with multiple sub-genre classifications. For example, rather than labeling a certain album rock, it might be post-punk and alternative. A modification to our analysis to obtain better prediction could involve changing our algorithms to output the percentages of the top three possible genre designations. This would actually be better at matching the bandcamp descriptions, as albums are typically described by several genres or keywords. Other features to be extracted from the images could also be considered. For example, the image gradients could be extracted in a similar way as the color histograms we extracted.
In conclusion, we chose a very difficult problem. It is difficult for people to classify genres in this fashion (only one genre per album), and our algorithms do not perform much better. Certain genres with more defined, consistent characteristics typically yield better results. It’s possible that the genres labels are too general and so include too many diverse artists, yielding varied cover art. Future work could include allowing multiple labels, collecting better-labeled data, and considering other possible features to extract from the images.
Here you can find our poster for this project, and here you can find our final report.