

Comparison of Machine Learning Approaches for Tsunami Forecasting from Sparse Observations
This was a project that I worked on with Christopher Liu, Donsub Rim, and Randall LeVeque. We attempt to predict maximum wave height, as well as full waveform, with several standard ML models. These are trained on GeoClaw runs. It has been accepted and set to appear in in Pure and Applied Geophysics as of July 2021, and preliminary ArXiv copy can be found here.
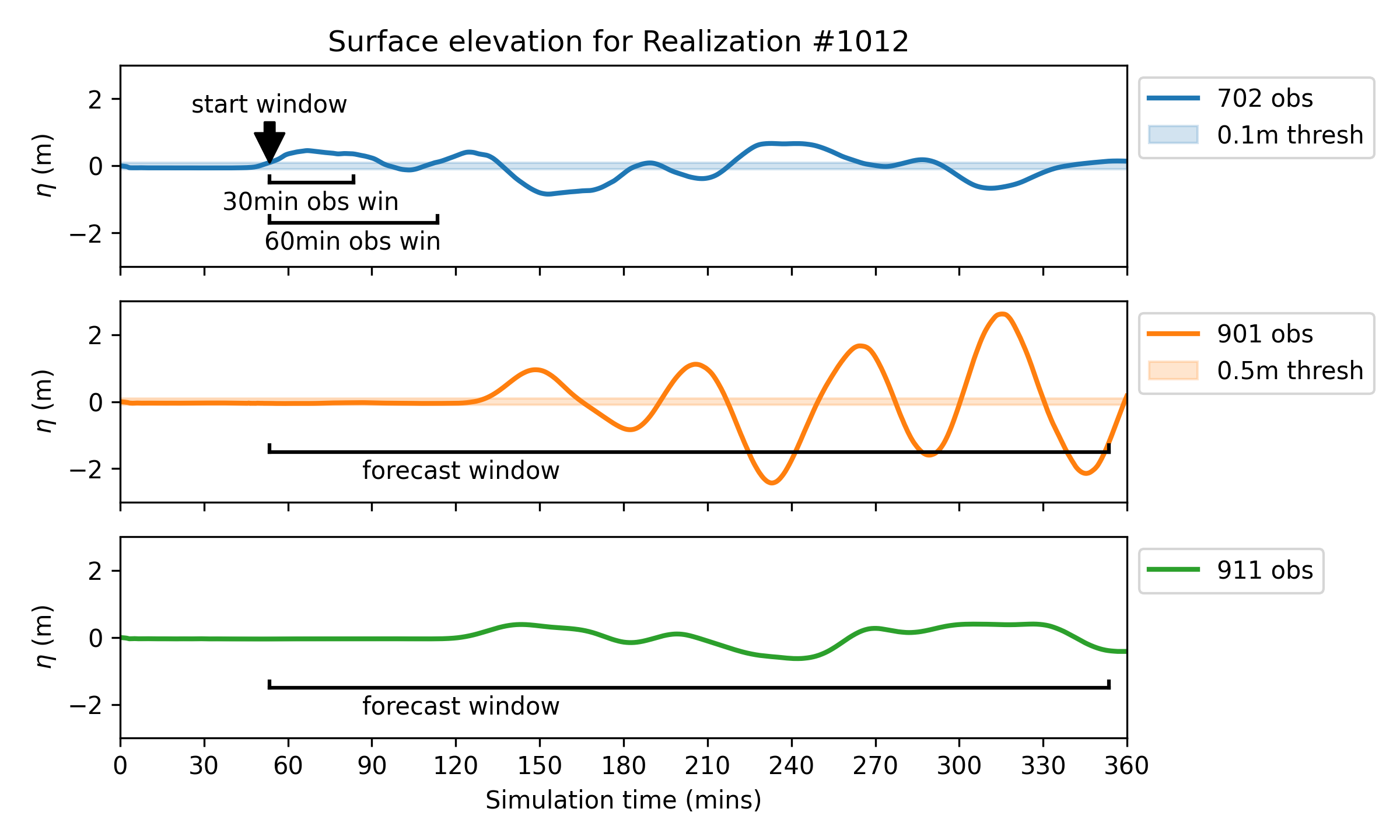
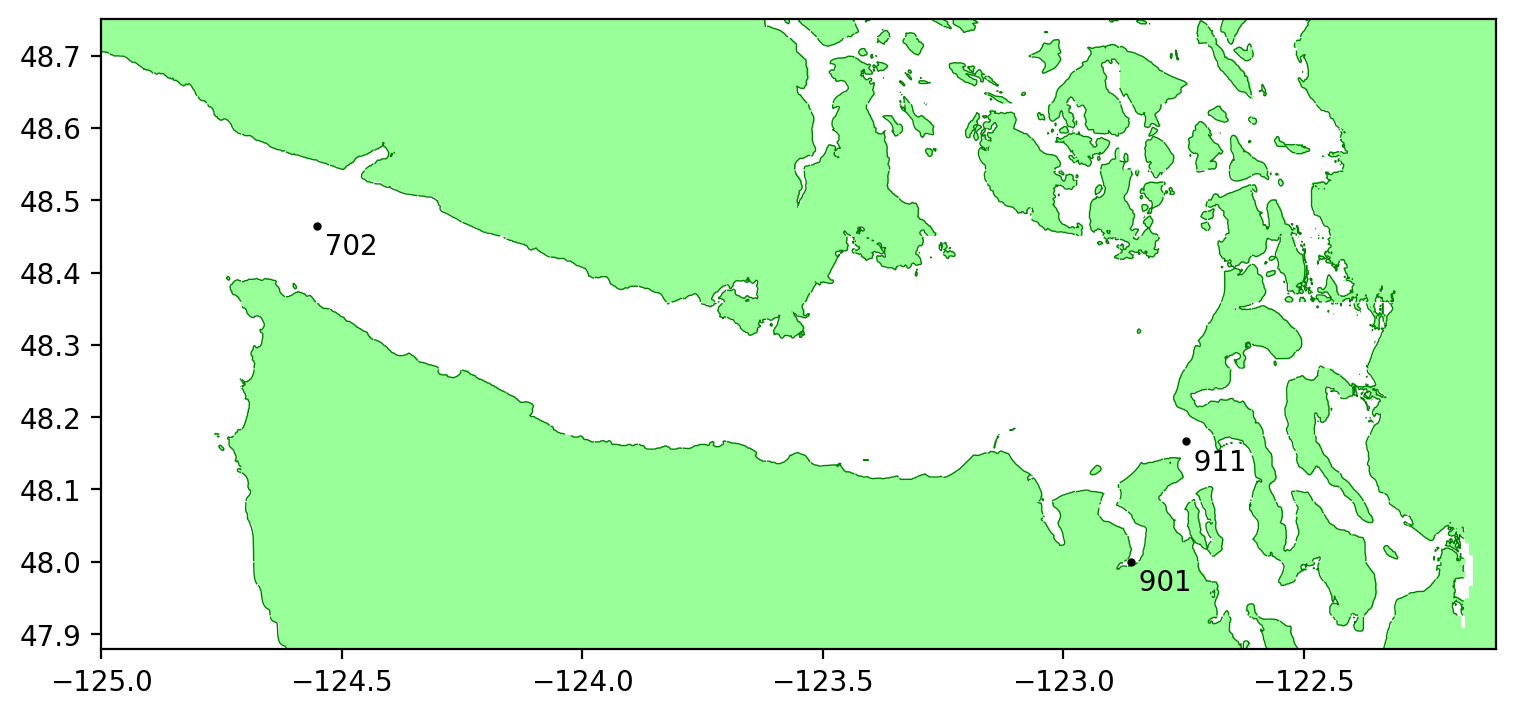
We have explored various different machine learning (ML) approaches for forecasting tsunami amplitudes % (or full time series) at a set of forecast points, based on hypothetical short-time observations at one or more observation points. As a case study, we chose an observation point near the entrance of the Strait of Juan de Fuca, and two forecast points in the Salish Sea, one in Discovery Bay and the other in Admiralty Inlet, the waterway leading to southern Puget Sound. One ML approach considered is to train a support vector machine (SVM) to predict the maximum amplitude at the forecast points. We also explored the use of two deep convolutional neural networks, a denoising autoencoder (DAE) and a variational autoencoder (VAE) to predict the full time series at the forecast points. These latter approaches also provide an estimate of the uncertainty in the predictions. As training data we use a subset of the 1300 synthetic CSZ earthquakes generated in the work of Melgar et al. 2016, reserving some as test data. As additional tests, the trained ML models have also been applied to other hypothetical CSZ earthquakes produced by very different approaches, such as the ``L1 event’’ from the work of Witter et al. 2013 that is used in the generation of tsunami inundation maps in Washington State. The ML models are capable of providing very good predictions from short duration observations, even when truncated before the first wave peak has reached the observation point.